Machine learning¶
A part of Core Ia: Introduction To Machine Learning And Statistics
Second half of Core Ia: Introduction To Machine Learning And Statistics
Same procedure as part 1 with lectures Tuesday and workshops on Friday
Course website: https://miscada-ml-2425.notes.dmaitre.phyip3.dur.ac.uk/

Notebook server: https://miscada-ml-2425.notebooks.danielmaitre.phyip3.dur.ac.uk/

I'm Will Yeadon and will be taking this course
Can contact me via email will.yeadon@durham.ac.uk
Office hours Monday 12:00 - 14:00 PH304 in Rochester Builing

Course Content
- Week 6: Introduction to machine learning, Perceptron, Logistic regression, Loss functions
- Week 7: ROC curves, Support vector machines, Non-linear models, Learning curves, Regularisation
- Week 8: Variance-Bias trade-off, Neural networks
- Week 9: Dimensionality reduction, Principal component analysis, Unsupervised learning, K-neighbours, ML in python: sklearn and pandas
What is Machine learning?¶
What is Machine learning?¶

Machine Learning¶
Machine Learning is a subset of artificial intelligence that focuses on enabling computers to learn from data and improve their performance over time without being explicitly programmed.
- Allows computers to identify patterns and make decisions with minimal human intervention.
- Utilized in various applications such as recommendation systems, speech recognition, and autonomous vehicles.
- Empowers organizations to make data-driven decisions.
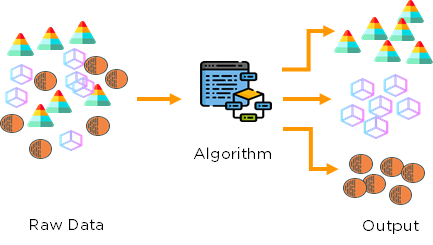
Machine learning algorithms can be classified according to:
- The type of problems they solve.
- The model they use.
- The way they learn.
- The type of data they process.
- The amount of human supervision involved.
Types of Problems¶
- Classification
- Output of the model is a discrete set of categories.
- Examples:
- Spam detection.
- Pion/proton discrimination.
- Positive/negative COVID test.
- Image recognition (identifying objects in images).
- Sentiment analysis (classifying text as positive, negative, or neutral).
- Fraud detection in financial transactions.
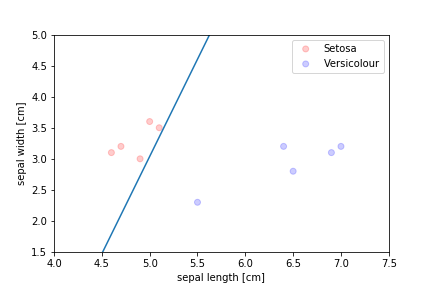
Classification¶
Types of Problems¶
- Regression
- Output of the model is a continuous variable.
- Examples:
- Value of stock.
- Country GDP.
- Predicting housing prices.
- Forecasting weather temperatures.
- Estimating the lifetime of a machine component.
Regression¶
Types of Problems¶
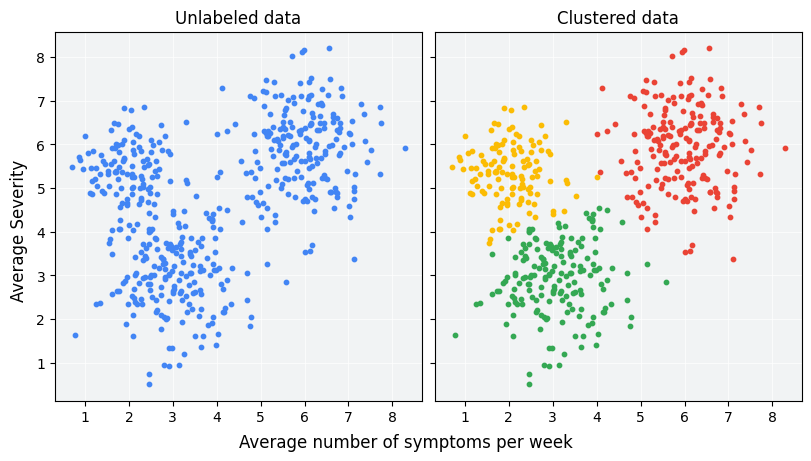
- Clustering
- Group data points into clusters based on similarity.
- Examples:
- Customer segmentation in marketing.
- Grouping genes with similar expression patterns.
Clustering¶
Types of Problems¶
- Dimensionality Reduction
- Reduce the number of features while retaining important information.
- Examples:
- Principal Component Analysis (PCA).
- Feature selection in high-dimensional data.
The boundary between the two types can be blurred:
- When the categories have an ordering, we can use regression and bin the result into categories:
- A*, A, B, C, etc., grades.
- Number of stars for a review.
- Energy rating of a building.
- Credit score ratings.
- For classification, we can fit a function for the probability of belonging to one class:
- Logistic regression outputs probabilities between 0 and 1.
- Softmax function used in multi-class classification.
Some problems can be approached using either classification or regression techniques, depending on the desired outcome.
Types of Learning¶
- Supervised Learning
- We have a training set with labeled examples.
- The algorithm learns a mapping from inputs to outputs.
- Examples:
- Predicting house prices based on historical data.
- Classifying emails as spam or not spam.
Regression¶
Types of Learning¶
- Unsupervised Learning
- No labeled examples.
- The model has to find patterns or features.
- Can be used as a first step before supervised learning.
- Examples:
- Clustering customers based on purchasing behavior.
- Reducing dimensionality for data visualization.
Unsupervised Learning¶
Types of Learning¶
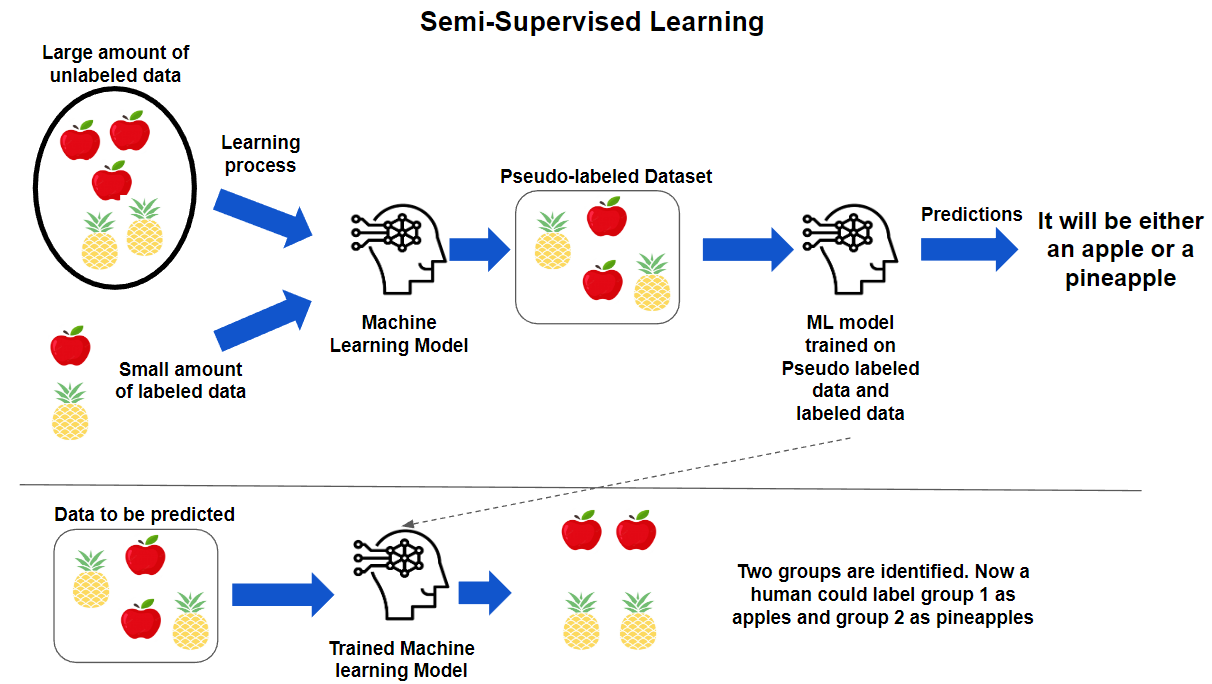
- Semi-supervised Learning
- Uses both labeled and unlabeled data.
- Helps when labeled data is scarce or expensive to obtain.
- Examples:
- Web content classification with limited labeled pages.
Semi-supervised Learning¶
Types of Learning¶
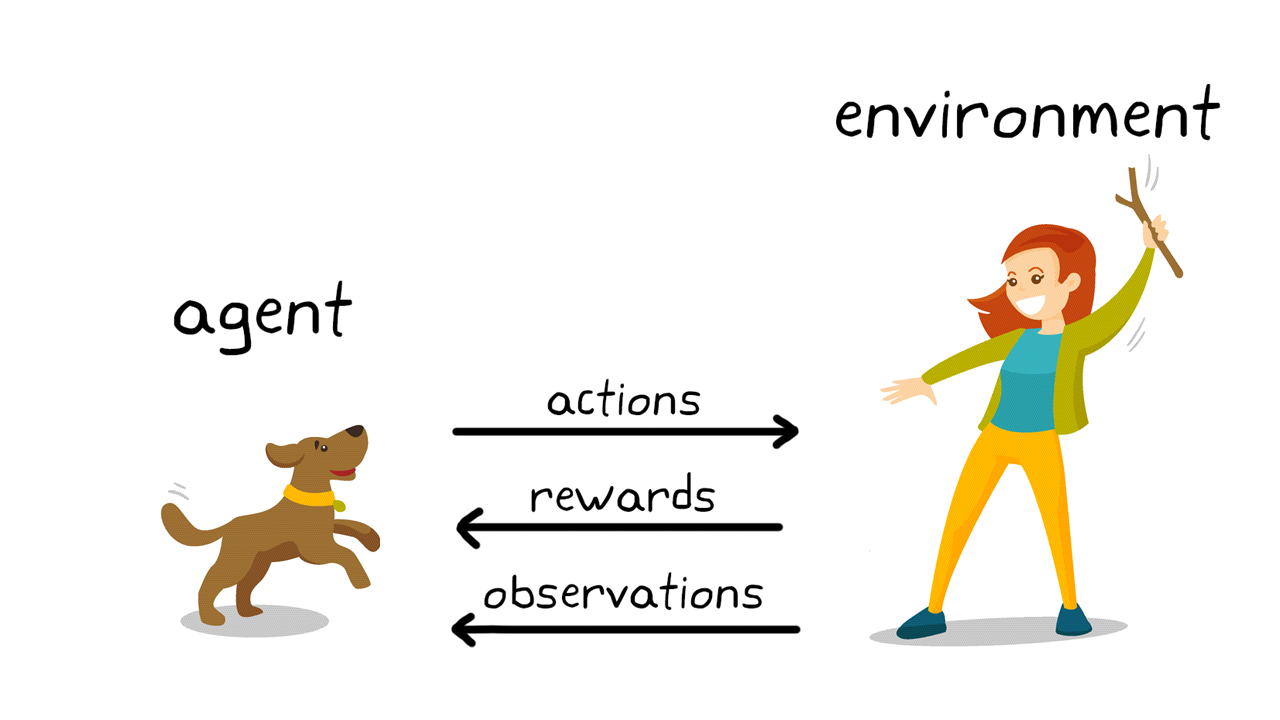
- Reinforcement Learning
- The model learns by interacting with an environment.
- Receives rewards or penalties based on actions.
- Goal is to maximize cumulative reward.
- Examples:
- Game-playing AI (e.g., AlphaGo).
- Robotics and autonomous vehicles.
Semi-supervised Learning¶
Learning Modes¶
- Batch Learning
- The entire training set is used for each iteration of the model optimization.
- Requires significant memory and computational resources.
- Online Learning
- The model is updated for each new training example.
- Suitable for data that arrives in a stream or is too large to process all at once.
- Mini-batch Learning
- The model is optimized for subsets of the training set.
- Balances between batch and online learning.
- Improves computational efficiency and convergence stability.
Choosing the right learning mode depends on the dataset size and computational resources.

Batch Learning¶
The entire training set is used for each iteration of the model optimization.
Advantages:
- Stable convergence as it considers all data at once.
- Suitable for smaller datasets.
Disadvantages:
- Not scalable for very large datasets.
- High memory usage.

Online Learning¶
The model is updated incrementally as each new training example arrives.
Advantages:
- Can adapt to new data and changing environments.
- Suitable for real-time systems.
Disadvantages:
- May have less stable convergence.
- Requires careful tuning of learning rate.

Mini-batch¶
The model is optimized using small subsets (batches) of the training set.
Advantages:
- Reduces memory usage compared to batch learning.
- More computationally efficient than online learning.
- Smoother convergence than pure online learning.
Disadvantages:
- Requires choosing an appropriate batch size.
- May still be challenging with extremely large datasets.
Instance-based vs Model-based¶
- Instance-based
- Uses specific examples from the training data to make predictions.
- Relies on a similarity measure to compare new data to training data.
- Also known as "lazy learning" because it delays processing until a query is received.
- Model-based
- Abstracts from the training data to build a model that can make predictions.
- The data fixes the parameters of the model during training.
- Also known as "eager learning" because it builds the model before receiving queries.
The choice between instance-based and model-based methods depends on the problem at hand.
Example: Predicting final grade \( g_4 \) of a student given their 1st, 2nd, and 3rd-year results \( g_1 \), \( g_2 \), and \( g_3 \).
- Instance-based:
- Look at historical results and find the student(s) with the closest marks to the current student.
- Use the final grades of those past students as the prediction for the new student.
- Could average the final grades of the nearest neighbors.
- Model-based:
- Hypothesize a linear dependency: $$ g_4 = c_1 g_1 + c_2 g_2 + c_3 g_3 $$
- Fit the coefficients \( c_1 \), \( c_2 \), \( c_3 \) to historical data.
- Use the model to predict the new student's final grade.
This illustrates the fundamental difference in approach between the two methods.
Examples of Model-based Algorithms¶
- Linear Models
- Perceptron.
- Linear Regression.
- Logistic Regression.
- Support Vector Machine (SVM) with linear kernel.
- Non-linear Models
- Polynomial Regression.
- Decision Trees.
- Neural Networks.
- Random Forests.
- Support Vector Machine with non-linear kernels.
- Probabilistic Models
- Naive Bayes Classifier.
- Hidden Markov Models.
Model-based algorithms are powerful for capturing underlying patterns in data.
Examples of Instance-based Algorithms¶
- \( k \)-Nearest Neighbors (k-NN)
- Support Vector Machine (SVM) with Radial Basis Function (RBF) kernel
- Locally Weighted Learning
- Case-based Reasoning
- Kernel Regression
Instance-based methods are simple and effective for certain types of problems.
Summary¶
In this lecture, we covered the following key concepts in Machine Learning:
- Types of Problems: Classification, Regression, Clustering, and Dimensionality Reduction.
- Learning Modes: Batch, Online, and Mini-Batch Learning with their respective use cases and trade-offs.
- Types of Learning: Supervised, Unsupervised, Semi-supervised, and Reinforcement Learning.
- Instance-based vs. Model-based Methods: Differences in how data is utilized for making predictions.
Machine Learning is a broad and evolving field that bridges data, algorithms, and real-world applications. Understanding these concepts forms a solid foundation for deeper exploration into modern ML techniques and applications.
Perceptron¶
Perceptron¶
The Perceptron algorithm was the first "machine learning" algorithm.
- Invented in 1957 by Frank Rosenblatt.
- Designed to perform binary classification tasks.
- Forms the foundation for neural networks and deep learning.

Classification¶
We have a set of examples of items from two classes. We want to train a model to distinguish between the two classes for new items.
Notation¶
Training data is composed of $n_d$ samples, each of which has $n_f$ features. Each data sample's class label is encoded as $\pm 1$.
$$\mbox{features: }\quad x^{(i)}_j,\qquad 1\leq i\leq n_d\,,\qquad 1\leq j \leq n_f $$ $$\mbox{labels: }\quad y^{(i)} = \pm 1\,,\qquad \qquad 1\leq i\leq n_d $$Model¶
We will train a linear model
$$ z(x, w) = w_0 + \sum_j x_j w_j $$with $n_f+1$ parameters
$$ w_j\,,\qquad 0 \leq j \leq n_f $$We will use the decision function
$$ \phi(z)= sgn(z) $$If $\phi(z)=+1$ our model predicts the object to belong to the first class, if $\phi(z)=-1$ the model predicts that the object belongs to the second class.
Now we need to set the parameters $w_j$ such that our pediction is as accurate as possible.
Perceptron Algorithm¶
Go through all the training data set and for each sample:
- calculate the prediction of the model with the current parameter
- if the prediction for $x^{(i)}$ is correct:
- move to the next sample
- if the prediction for $x^{(i)}$ is incorrect:
- adjust the parameter according to $$\begin{eqnarray}w_j &\rightarrow& w_j + \eta y^{(i)} x^{(i)}_j\,,\quad 1\leq j \leq n_f \\ w_0 &\rightarrow& w_0 + \eta y^{(i)}\end{eqnarray}$$
- move to the next sample
Repeat the procedure until no more examples are wrongly predicted (or until a small enough amount fails)
Each repeat is called an epoch.
Some references give the perceptron algorithm with a fixed value of $\eta$.
It is convenient to add a $1$ as the 0-th component of the data vector $x$
$$\vec{x} = 1, x_1, ... , x_{n_f}$$so that the linear model can be written as
$$ z(x,w) = \vec{x}\cdot \vec{w} $$This allows to write the update rule for the perceptron algorithm as
$$ \vec{w} \rightarrow \vec{w} + \eta\, y^{(i)}\, \vec{x}^{(i)} $$Learning rate¶
The parameter $\eta$ in the update rule
$$\begin{eqnarray}w_j &\rightarrow& w_j + \eta y^{(i)} x^{(i)}_j\,,\quad 1\leq j \leq n_f \\ w_0 &\rightarrow& w_0 + \eta y^{(i)}\end{eqnarray}$$is a parameter of the algorithm, not a parameter of the model or of the problem. It is an example or hyperparameter of a learning algorithm.
The learning rate set how much a single misclassification should affect our parameters.
- a too large learning rate will lead to the paramters "jumping" around their best values and give slow convergence
- a too small learning rate will make more continuous updates but it might take many epochs to get to the right values
Convergence¶
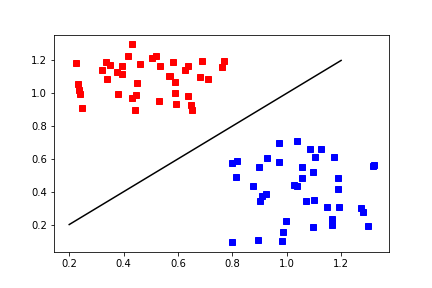
The perceptron algorithm is converging if the classes are linearly separable in the training set.
It might take a long time to converge
Linearly separable¶
Separable, but not linearly¶
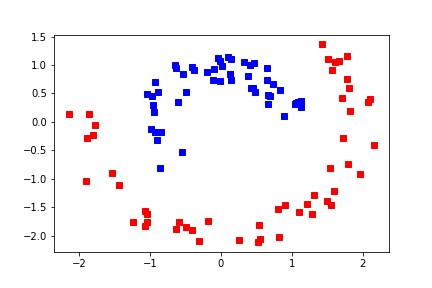
Probably not separable¶
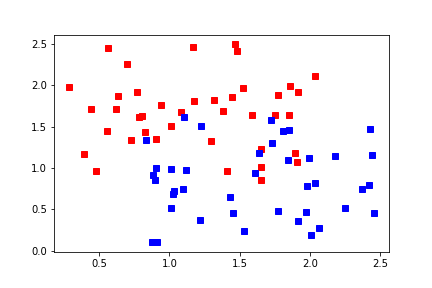
Problems with the perceptron algorithm¶
- convergence depends on order of data
- random shuffles
- bad generalisation
Bad generalisation¶
The algorithm stops when there is no errors left but often the demarcation line ends up very close to some of the instances, which leads to bad generalisation